Standardized Information Sharing in Supply Chain Management
Introduction:
In supply chain management, effective standardized information sharing relies on three key pillars: digitization of documents and information, utilization of collaborative platforms, and standardization of documents and information formats. Each of these pillars is essential, as they collectively contribute to ensuring secure, fully digital collaborative document and information exchange capabilities.
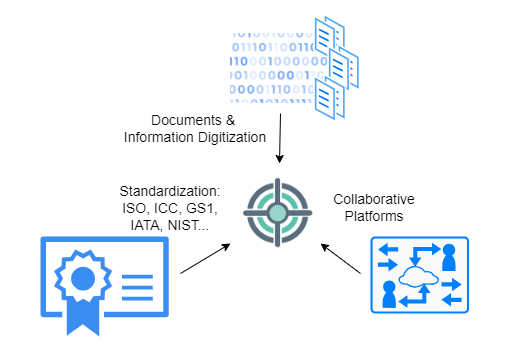
Below are detailed descriptions of each of the pillars, along with examples of what a good framework for standardized information exchange should look like:
.
Documents & Information Digitization: Proper digitization and availability of documentation are paramount for shipments to arrive on time. While many documents are digitized, achieving a unified view of all documents in a uniform and timely manner remains a challenge:Documents Digitization:
- All documents should be converted to digital formats, including identification and classification of standardized data elements. Digitized documents and their associated digital elements should then be readily available to all parties on a need-to-know basis.
- The platform enabling access to the documents should be capable of extracting values from data elements and associating them with a shipment in the context of the document type.
Information Digitization:
- Any information related to logistics or business events of the shipment should be transformed into its digital format and associated with the shipment. Examples include user interaction with the shipment during logistics or business activities, tracker information about temperature, shock, humidity, etc., any missing steps of SOPs, and others.
Timely Digital Recording of Information:
- Minimize or eliminate delays between event occurrence and event recording by employing intelligent automation.
- Encourage and/or enforce users to interact with the platform via notifications to submit missing information.
.
Documents & Collaborative platforms Once information is digitized, procedures must be established regarding what information should be shared and who should have the privilege to view it. The process of sharing should be flexible, transparent, and, above all, secure. Below are items that need to be considered:Collaborative platforms configuration:
- Easy process to onboard and suspend users
- Define and modify users roles
- Define and remove locations
Flexible, secure, and auditable access control for granting and removing access to shared information based on:
- Granularity of the information (i.e., for luxury shipments, one can monitor conditions but not see the location; for personalized therapies, one can see all locations but not the destination, serial number of the trade, and logistic items).
- Party identity accessing shared information.
- Date, time, and geographical location of the party accessing the information.
- Type of shipment.
- Geographic location of the shipment for the entire shipping lane or just for a chosen portion of the shipping lane.
Data protection and privacy laws:
- Ability to configure data export policies compliant with data residency laws enforceable at the shipment level.
- Compliance with data protection laws, preventing unintended data disclosures.
Immutable and auditable store of records:
- Audit of critical shipment records including monitored key performance indicator (KPI) excursions, process deviations, and changes to shipping milestones.
- Security audit of records includes monitoring access granting and removal, as well as any changes related to user access permissions.
.
Standardization of Documents & Data Elements: Finally, the standardization of documents, along with the identification and classification of standardized data elements, is pivotal for achieving a consistent representation of vital information commonly found in documents used across supply chain management.Another standard related to interoperability of operational data is the GS1 Business Vocabulary, which provides standardized identifiers, codes, and attributes for describing products, locations, parties, transactions, and more.
Notable efforts by the ICC through its Digital Standards Initiative project and the GS1 Business Vocabulary lay the groundwork for standardizing document data, providing a fundamental framework for enhanced interoperability and efficiency in supply chain operations.
The International Chamber of Commerce:
- ICC-DSI publication) identified 37 different types of documents commonly used in supply chain management. The documents range from Finance & Payment to Transport & Logistics, Document of Title, Product related certificates, documents for export, import and transit, and documents related to customs
GS1:
- GS1 Core Business Vocabulary is a collection of vocabulary identifiers and definitions with the aim to support frictionless exchange of information related to supply chain management activities.
.
Conclusion:
As supply chain management becomes increasingly complex and trade volumes rise, securely and timely sharing information between various stakeholders becomes imperative. In this era of leveraging Artificial Intelligence, including machine learning and intelligent automation, the initial step is to digitize supply chain management, thereby implementing frameworks that enable data standardization and secure access between parties.
The above three pillars should serve as guidelines for supply chain management parties to understand the necessary capabilities required to enable frictionless digital collaboration.
Our Journey in GenAI
In nearly every meeting with our customers, we’re faced with questions:
- Are you exploring GenAI?
- Does your product incorporate GenAI?
- What are the applicable use cases for GenAI?
At KatalX, while we currently have two ongoing projects involving GenAI, our journey began with an analysis of how GenAI could generate new content from existing data for use in Supply Chain Management (SCM), with a particular focus on the Life Sciences sector.
Our analysis revealed that the utilization of GenAI is constrained by challenges related to explainability and model training. Below, we present a summary of our analysis along with suggestions for addressing these challenges.
We’ve classified the challenges into four groups:
Challenge #1:
- Difficulty in identifying training data due to the complexity and opacity of SCM processes involving multiple parties, as well as the challenge of correlating data collected during business and logistical activities.
.
Challenge #2:
- Dilemmas in explaining GenAI models’ compliance with legal frameworks and guidelines such as CFR21, GMP, GDP, or ISO27001.
.
Challenge #3:
- Conundrums arising from the necessity to protect data privacy during logistical operations within the rapidly expanding market of Personalized Therapies. As these therapies are tailored to individual patients, it is crucial that logistic units (such as parcels and labels) do not reveal any patient-related data. While regulations like HIPAA (US), GDPR (EU), and LGPD (Brazil) have not traditionally been integrated into SCM practices, this is expected to change in the near future.
.
Challenge #4:
- Difficulty in ensuring that GenAI produces accurate outcomes for supply chain operations. With personalized therapy costs often reaching tens or hundreds of thousands of dollars, using newly generated GenAI data for supply chain management products may pose significant risks.
.
Unsurprisingly, the remedies stem from underlying data analytics fundamentals:
- the availability of high-fidelity data and
- flexible framework that accommodates changing regulations, alongside applied data confidentiality practices.
.
Let’s review how each of these challenges can be addressed:
Remedy #1:
- Implement a cointegration process for data in time, space, and business context to create repositories of high-fidelity data suitable for quantitative modeling. Cointegrated data dimensions also enable the reduction of required number of data observations to obtain meaningful output from GenAI models. Additionally, ensuring copyright protection for trained data allows for the use of derivative works from GenAI models.
.
Remedy #2:
Explore various approaches to explainability in the context of generative AI, such as
- and preferred method Proxy Models. Proxy Models, in particular, are a common technique used in quantitative analysis in scenarios where regulators require understanding of decisions driven by black box models like LLM. Proxy Models necessitate the use of high-fidelity data.
.
Remedy #3:
- Recognize that Data Confidentiality is transitioning into Supply Chain Management as a necessity rather than merely an option. Protecting data on a need-to-know basis through flexible configuration will determine the effectiveness of supply chain management platforms in personalized therapies.
.
Remedy #4:
- Ensure the viability of GenAI outputs by applying feedback constraints anchored in financial, sustainability, and resiliency goals. Supply Chain Management may need to utilize a combination of GenAI and more traditional models to ensure alignment with the organization’s business goals.
.
While our journey to prove the value of generative AI continues, we’ve successfully applied most of the remedies listed above. We aim to share our successes to benefit supply chain management customers and ultimately patients themselves.
We encourage you to reach out to us to share your opinions on how our industry can further improve supply chains, and hopefully serve a long-term vision of fostering “antifragile” supply chains: supply chains that effectively reinforce themselves with shocks and disruptions.
.
Tom Z.,
Join Our CYBERSPACE Study: Shaping Cybersecurity Strategies Together

KatalX is proud to be part of the Trust Valley, the Swiss-based innovation ecosystem between Geneva and Lausanne, which focuses on fostering #DigitalTrust, and promoting higher levels of #cybersecurity in the global economy especially in #supplychains…